

This is a three-part guide on how to replicate Google Analytics data on Google BigQuery, using singer.io’s taps and targets that helps orchestrate the replication process.
Tools Used
- Singer.io: Open source replication framework
- Google Analytics Tap: Python package to extract GA data
- Google BigQuery Target: Python package to load data into BigQuery
Table of Contents
- Setting up local environment (This guide)
- Dockerising the setup (Part 2)
- Setting up replication schedule on Kubernetes (Coming soon)
Introduction
If you rely heavily on Google Analytics to keep track of your website/app’s usage statistics, it’s often difficult to get a hold of the raw data to do in-depth analysis, or simply improve your reporting.
You either need to go big and upgrade to GA 360 (which can cost upwards of $100K/year) or rely on third party replication platforms such as Supermetrics, Fivetran or Stitch. The cost attached to the latter can vary depending on the amount of data you want to replicate, however it’s safe to assume it’ll be at least $200/month.
While recently dealing with this very problem with cost implications in mind, I’ve discovered singer.io, which is an open source framework for facilitating replication process between different sources (GA, Google Ads, Hubspot etc) and destinations (Google BigQuery, MySQL, CSV).
It works based on the simple premise of facilitating the data flow between the data sources (called taps) and destinations (called targets) using Linux pipes.
Singer taps are Python packages that extract the required data from a specific data source’s API and standardising the output for Singer pipeline.
Singer targets are Python packages that write the standardised output from the tap to the destination database.
In this guide, I will set up a pipeline to extract data from Google Analytics (using a Singer tap) and feeding that into Google BigQuery (using a Singer target).
Installing the GA Tap and BigQuery Target
The first step will be to install the required Singer tap and target in the project directory. I strongly recommend installing each tap and target inside their own Python virtual environments to prevent any compatibility issues for packages’ dependencies.
For this exercise, I will use the GA tap and BigQuery target I’ve developed. Both packages require Python 3.8, so make sure you have it installed in your system.
1python -m venv env-tap2source env-tap/bin/activate3pip install --upgrade git+https://github.com/saidtezel/tap-google-analytics.git4deactivate56python -m venv env-target7source env-target/bin/activate8pip install --upgrade git+https://github.com/saidtezel/target-google-bigquery.git9deactivate
Configure Tap/Config Settings
Next step is to create the necessary config files for tap and target, and place it in the project directory.
Tap Config
For Google Analytics tap, we will need two files:
- A
tap-config.jsonfile that will define the GA specific parameters - A
service-account.jsonfile that will authenticate the GA API. You can follow the guide here to create a Service Account and create a key file in JSON format. You will also need to ensure that the email address for the service account is added to your GA account with view permission on the property.
For tap-config.json file, there are a few different parameters you can tinker with, details for which you can find on the Github repo. At the bare minimum, however, you’ll need three parameters.
key_file_location: The filename for the service account, which should be placed on project root.view_id: The GA view ID you’d like to query.start_date: ISO formatted start date for the reporting. All the GA from this date onwards will be queried.
1// tap-config.json23{4 "key_file_location": "service-account.json",5 "view_id": "1234566",6 "start_date": "2018-01-01T00:00:00Z"7}
If we don’t define a custom report configuration, this tap will by default extract a few different reports from GA, as defined here. If you take a look at the default definitions file, you will notice that it’s another JSON file that holds an array with multiple objects. Each object defines a report name, list of dimensions and list of metrics.
If you’d like to create your own report definitions, you will need to create a reports.json file in your project root, and populate it with your select dimensions and metrics similar to what you’ve seen on the default_report_definition.json file.
You can find a list of available dimensions/metrics and their IDs here.
Once you have your reports.json file ready, you will need to update the tap-config.json file to instruct it to look at our new file for report definitions.
1// tap-config.json23{4 "key_file_location": "service-account.json",5 "view_id": "1234566",6 "start_date": "2018-01-01T00:00:00Z",7 "reports": "reports.json" // Our custom report definitions file.8}
Target Config
For the BigQuery target, we only need a target-config.json file. Although there are different parameters yuo can adjust (check the repo for more detail), there are three parameters that has to be defined.
project_id: Project ID for the Google Cloud projectdataset_id: Dataset ID created inside BigQuery. All the tables from this pipeline will be replicated inside this dataset.key_file_location: The filename for the service account, which should be placed on project root. This can refer to the same service account file you’ve created for GA.
1// target-config.json23{4 "project_id": "bigquery-public-data",5 "dataset_id": "samples",6 "key_file_location": "service-account.json"7}
Running the Tap for the First Time
Once we create all the config files and service account file, and place it on the project dir, we are ready to run the pipeline for the first time.
In the command line, you will need to enter the following command. You will notice that it’s actually two separate commands separated by a pipe. That pipe inbetween means that whatever data is output from the first command (our GA tap) will be fed into the second command (our BQ target) as an input.
1env-tap/bin/tap-google-analytics --config tap-config.json | env-tap/bin/target-google-bigquery --config target-config.json
Once the command is triggered, you should see the data extraction process.
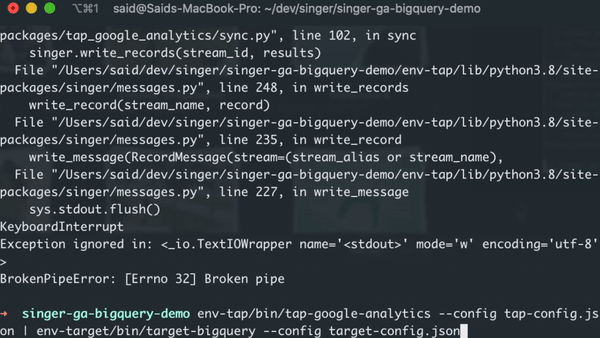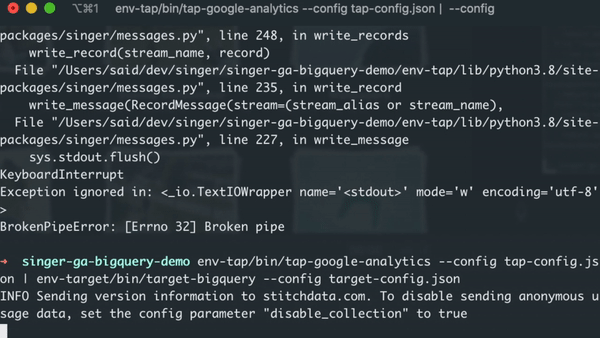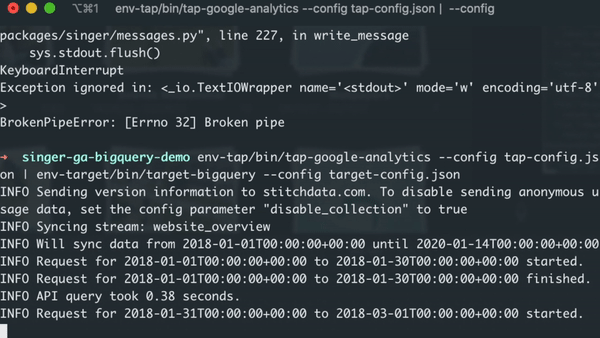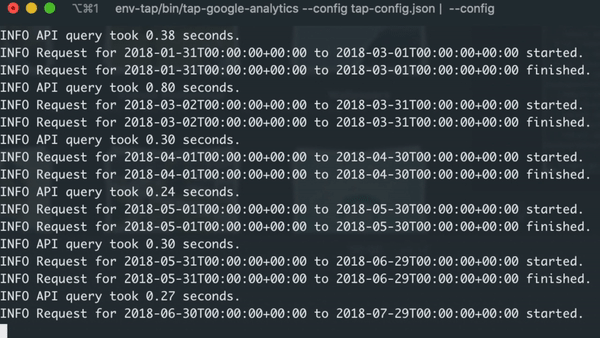
Pulling Incremental Data
If you ran the previous command and saw your data successfully replicated on BigQuery, well done! Now you may be wondering, what happens when I run the pipeline again?
By default, this command will pull all the GA data available between the start_date defined in tap-config.json file and today. If you’re thinking about running this pipeline at set intervals, however, it means that it will re-sync data for all the previous dates we already have in our destination database. This also means that we would be unnecessarily exhausting our GA API quota, and adding duplicate rows on BigQuery tables.
In order to avoid such an issue, we will make use of a singer.io feature called state. A Singer tap with state feature (such as my GA tap) ensures that metadata about our pipeline runs are logged in a JSON file, reusable at the next runs.
I utilise state in my GA tap in the form of logging timestamps for the last extracted date for each report definition. This way, if my pipeline breaks at any point due to an error, the state.json file will log the last complete day extracted. When I re-run the pipeline, I will be pass the state.json file as an input parameter. That way, the GA tap will only sync the data from the last checkpoint logged in the state.
In order to make our pipeline stateful, we need to make a small change in our initial command:
1env-tap/bin/tap-google-analytics --config tap-config.json | env-tap/bin/target-google-bigquery --config target-config.json > state.json
Notice that we are asking the final output of the pipe operation to be written to a local state.json file.
When we run the pipe like this, and let it successfully finish, it will have created a new state.json file in the project directory. In the subsequent runs, we simply pass this state.json file as an input parameter.
1env-tap/bin/tap-google-analytics --config tap-config.json --state state.json | env-tap/bin/target-google-bigquery --config target-config.json > state.json
If your date range is large and your website has a lot of traffic, the initial replication might take a while. Once the process is complete, you can check your BigQuery dateset to make sure that everything’s in order.
Next Steps
Now that we have successfully managed to create the pipeline, the next step is to automate it. You can check part 2 for the next steps.
